We train models to explain their own internal computations, such as what their features respond to or how those features affect the output. We find evidence that models have privileged access to these computations, and use this to train data-efficient explainer models.
Summary
Language models can produce fluent explanations of their decisions, for instance via their chain-of-thought. However, despite sounding plausible, these explanations often don't reflect the model's actual decision process [1, 2, 3]. This isn't surprising: nowhere in the training pipeline is a model ever expected to be faithful to its internal computation.
What if we did train models to faithfully verbalize their internal computations? We might hope that such models could explain what features were active in their representations, as well as the true causal relationship between the input tokens, the latent features, and the model outputs.
To approach this, we start from interpretability methods that provide ground-truth data about model internals—for example, automatic feature description explains neural features (e.g. from sparse autoencoders or neurons) by summarizing the contexts that activate the feature. We train explainer models to produce these ground-truth explanations given the activations of the target model that we are explaining. We find that models trained on this data can generalize to new instances of these queries about their own internals, including to out-of-distribution queries.
Even more strikingly, we find a consistent pattern of models exhibiting privileged access to their internals: models can explain their own computations better than others can. This suggests that models can be trained to have introspective access to their own internal structure [4].
Finally, our full paper includes a set of scaling experiments showing that self-explanations are significantly more data efficient than other explanation techniques. Interpretability tools today are powerful but costly—they require manual engineering or expensive search. Self-explanation enables generalization to new queries with far fewer ground-truth interpretability examples.
Training Models to Self-Explain
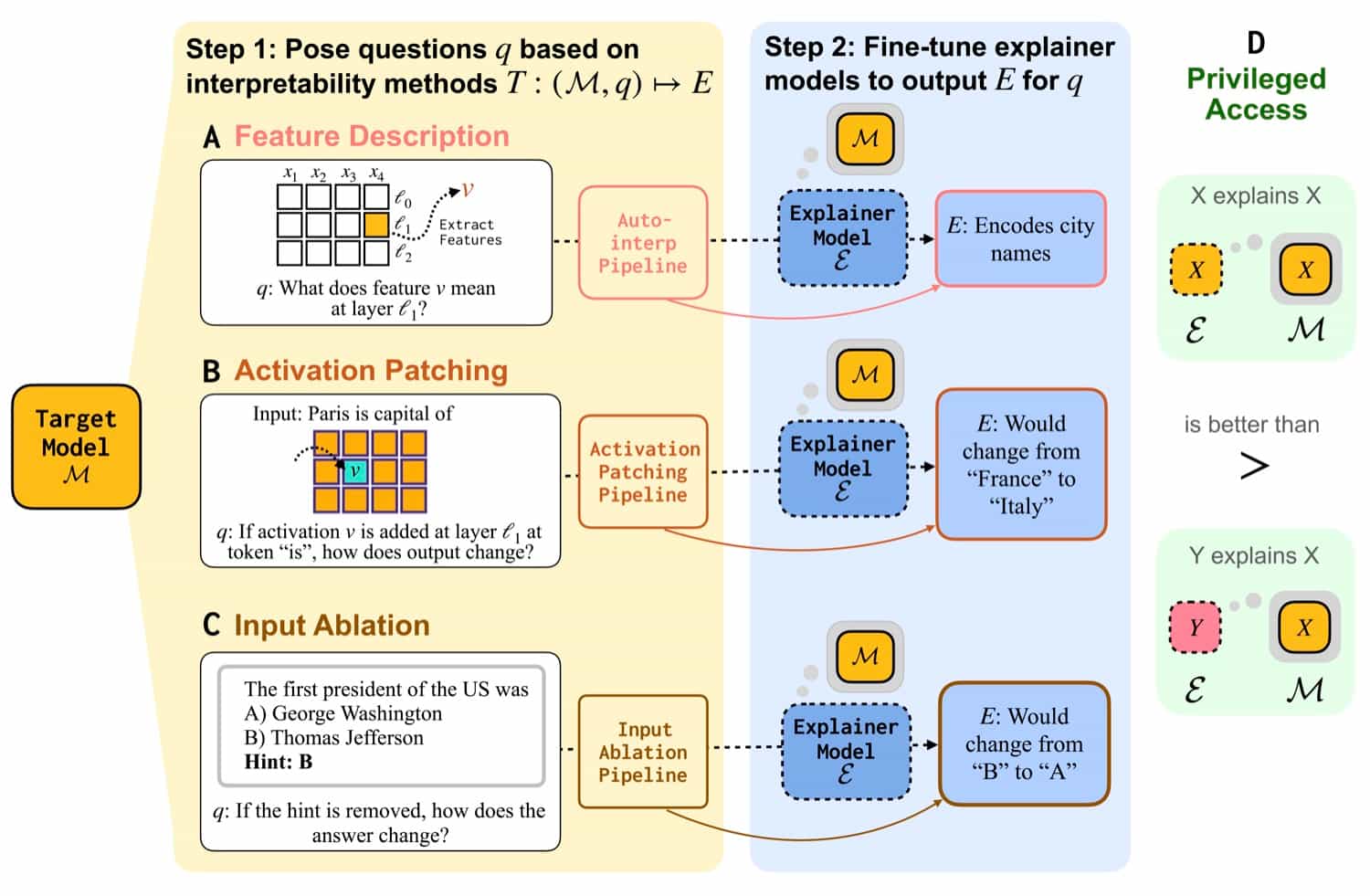
We elicit three different types of internal computation from a target model (the model that we are explaining):
- What does a model-internal feature represent? We use auto-interpretability pipelines to generate explanations of the kinds of inputs that activate a feature (Feature Description, Fig 1A).
- What components of models' internals affect their prediction? We conduct interventions to models' internal activations to isolate important components, and expect explanations to describe the intervention outcome (Activation Patching, Fig 1B).
- What tokens are important to a models' decision? We ablate tokens in the input to identify boundaries of their decision rules (Input Ablation, Fig 1C).
We then fine-tune various explainer models on each of these three types of questions.
Evidence for Privileged Access
We find that explainer models trained on the explanations from these interpretability procedures can describe new features, new intervention outcomes, and new decision boundaries. In particular, we find that explainer models trained to explain themselves are better than explainer models trained to explain other models, in line with privileged access.

We also perform a set of scaling experiments, where we find that self-explanation is significantly more data-efficient than other explanation techniques, including training other models and a nearest neighbors SAE baseline. This suggests that self-explanations can be a scalable complement to interpretability techniques.
For more results and details, please refer to our paper.
How to Cite
@misc{li2025traininglanguagemodelsexplain,
title={Training Language Models to Explain Their Own Computations},
author={Belinda Z. Li and Zifan Carl Guo and Vincent Huang and Jacob Steinhardt and Jacob Andreas},
year={2025},
eprint={2511.08579},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.08579},
}